É sempre esperado que as aplicações utilizem os recursos computacionais da forma mais otimizada possível, evitando o desperdício, como em cenários de infra super dimensionada, assim como se atentando para não ocorrer sobrecarga de trabalho, como em situações de infra subdimensionada, causando problemas de performance.
Em ambientes que possuem múltiplos processadores, o uso de técnicas de paralelismo na aplicação pode aumentar o throughput, distribuindo a carga em tarefas menores e realizando as operações paralelamente.
O .NET possui uma série de recursos que possibilitam a realização de paralelismo, permitindo desde o gerenciamento total das threads, até a utilização de abstrações de alto nível para a distribuição da carga.
Conceitos de multithreading
Ao iniciar uma aplicação, um processo é criado pelo sistema operacional. Sendo assim, o processo nada mais é do que a instância de um programa em execução. Conceitualmente, cada processo possui sua CPU virtual, capaz de realizar operações de forma independente, e não compartilhando endereços de memória com outros processos.
Uma thread pode ser definida como um mini processo, também capaz de realizar operações de forma independente. Threads são mais leves que processos, tornando a função de criação e destruição delas mais rápida, e consequentemente melhorando o desempenho.
Um processo pode possuir múltiplas threads, e cada thread pode executar uma operação diferente simultaneamente. Cada thread possui sua stack independente. No entanto, diferente dos processos, as threads compartilham endereços de memória (memória heap).
Considerações sobre paralelismo
Utilizar técnicas de paralelismo exigem maior consumo de CPU enquanto a operação é realizada. Em contrapartida, o throughput da operação aumenta.
É importante observar que, quanto mais independente o trabalho puder ser realizado, maior é a eficiência do paralelismo. Cenários que exigem o compartilhamento de estado entre threads, tornam-se menos eficientes, já que demandam a sincronização de acesso ao estado compartilhado.
Paralelismo em .NET
O thread pool é criado no momento que a aplicação é iniciada, com uma quantidade mínima de threads (que pode ser configurada), e, se adequa de acordo com a carga que a aplicação recebe, criando e destruindo threads. Além do gerenciamento do ciclo de vida das threads, o thread pool é responsável pela distribuição do trabalho, recebendo as tarefas, enfileirando-as e distribuindo-as entre as threads.
Considere como exemplo o seguinte método, que verifica se um número é primo:
private bool IsPrime(long number) { if (number == 2) { return true; } if (number % 2 == 0 || number <= 1) { return false; } for (long divisor = 3; divisor <= Math.Sqrt(number); divisor += 2) { if (number % divisor == 0) { return false; } } return true; }
Agora considere dois métodos, que chamam o método IsPrime e retornam a quantidade de números primos entre 1 e 200. A diferença entre eles é que o primeiro executa sequencialmente e o segundo em paralelo:
public long IsPrimeWithFor() { long result = 0; for (int number = 1; number < 200; number++) { if (IsPrime(number)) { result++; } } return result; } public long IsPrimeWithParrallelFor() { long result = 0; Parallel.For(1, 200, number => { if (IsPrime(number)) { Interlocked.Increment(ref result); } }); return result; }
Após realizar a comparação das soluções através da biblioteca BenchmarkDotNet, o resultado seguinte é apresentado:

Com o intervalo de números entre 1 e 200, e em um ambiente com 8 processadores lógicos, o método que realiza a operação sequencialmente apresentou um desempenho melhor, se mostrando aproximadamente 3 vezes mais rápido, e evidenciando que para esta implementação, e com um intervalo de valores relativamente pequeno, o paralelismo das tarefas não compensou. É sempre importante entender o cenário, realizar testes e avaliar se vale a pena a utilização do paralelismo.
 |
Dê preferência à utilização do tipo Parallel, ao invés de implementar seu próprio mecanismo de paralelismo. Dividir eficientemente as tarefas pode ser desafiador e contraprodutivo dependendo da dinamicidade dos dados. Parallel já possui mecanismos que lidam com o particionamento dos dados, e ajusta em tempo de execução de acordo com a necessidade. |
Deve-se utilizar paralelismo sempre que a carga puder ser distribuída?
Tipos de paralelismo em .NET
Há duas formas de paralelismo em .NET: data parallelism e task parallelism. Data parallelism está relacionado com cenários onde já existe um conjunto de dados, e cada dado pode ser processado independentemente. Task parallelism está relacionado com cenários onde existe um conjunto de operações para serem executadas, e cada operação pode ser realizada independentemente.
Data Parallelism:
public void ShowProductNames(IEnumerable<Product> products) { Parallel.ForEach(products, product => Console.WriteLine(product.Name)); }
Task Parallelism:
public void NotifyStakeholders(string message) { Parallel.Invoke( () => SendEmail(message), () => SendSmsMessage(message), () => SendTeamsMessage(message)); }
 |
Concurrency in C# Cookbook: Asynchronous, Parallel, and Multithreaded Programming Existem outras formas de realizar operações em paralelo com .NET, como por exemplo, operações utilizando PLINQ, que combinam a sintaxe LINQ com programação paralela. Esta e outras técnicas podem ser encontradas no livro “Concurrency in C# Cookbook”. |
Comparação de desempenho entre soluções
Devido à variedade de formas de implementar paralelismo em .NET, é comum surgirem dúvidas sobre a melhor solução. Apesar de existirem recomendações, há sempre exceções, demandando a avaliação de acordo com o cenário.
Considere novamente o exemplo do método que verifica se um número é primo, e observe os diferentes resultados de acordo com cada implementação utilizando paralelismo. Para este cenário, foi configurado um intervalo entre 1 e 1000000, em um ambiente com 8 processadores lógicos.
Solução #1 – A solução mais comum
Como base de comparação, analise a primeira implementação, utilizando um loop for comum, que itera sobre cada número de forma sequencial:
public long IsPrimeWithFor() { long result = 0; for (int number = _startNumber; number < _endNumber; number++) { if (IsPrime(number)) { result++; } } return result; }
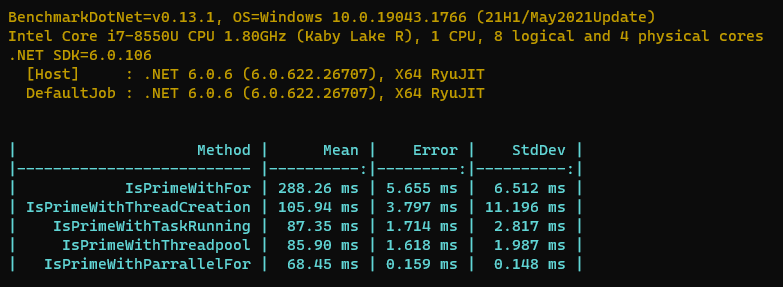
Esta operação levou em média 288.26 milissegundos. É um código simples e de fácil entendimento, até mesmo para alguém com pouca experiência, o que pode ser considerado um ponto forte, já que facilita a manutenção. Entretanto, existe uma chance significativa desse tempo ser considerado alto e insatisfatório para determinados cenários. O tempo de resposta pode ser ainda maior em cenários que demandam alta escala.
Independentemente de quantos processadores o ambiente possui, essa operação vai sempre realizar a verificação do número primo de forma sequencial, ainda que tenha processadores ociosos no momento da operação. Este é o motivo dessa implementação apresentar um tempo alto e potencialmente insatisfatório.
Solução #2 – Maximizando o uso dos processadores
A primeira solução é mais fácil de manter, porém, ela não aproveita eficientemente todos os recursos disponíveis de ambientes com múltiplos processadores, demandando a operação para somente um processador e deixando os demais ociosos. Entendendo que a carga pode ser distribuída e a operação executada de forma independente, o ideal seria paralelizar as verificações de números primos:
public long IsPrimeWithThreadCreation() { long result = 0; var range = _endNumber - _startNumber; var numberOfThreads = Environment.ProcessorCount; var threads = new Thread[numberOfThreads]; var chunkSize = range / numberOfThreads; for (var i = 0; i < numberOfThreads; i++) { var chunkStart = _startNumber + chunkSize * i; var chunkEnd = i == numberOfThreads - 1 ? _endNumber : chunkStart + chunkSize; threads[i] = new Thread(() => { for (var number = chunkStart; number < chunkEnd; number++) { if (IsPrime(number)) { Interlocked.Increment(ref result); } } }); threads[i].Start(); } foreach (var thread in threads) { thread.Join(); } return result; }
O código ficou significativamente mais complexo. Em contrapartida, o tempo médio de execução foi de 105.94 milissegundos, quase três vezes mais rápido que na primeira solução. Nesta implementação, a verificação de números primos acontece de forma distribuída e independente, demandando o trabalho para todos os processadores, onde cada thread fica responsável pela verificação de um conjunto de números.
A verificação de um número primo acontece de forma independente, porém, o incremento da variável result, responsável pela quantidade de valores primos, demanda a sincronização das threads. A sincronização é necessária para evitar que múltiplas threads leiam o mesmo valor e incrementem ao mesmo tempo, baseadas em um valor desatualizado. A sincronização acontece na linha de código Interlocked.Increment(ref result), garantindo que somente uma thread por vez terá acesso à variável result.
Solução #3 – Utilizando técnicas mais modernas de paralelismo
O código da segunda solução apresentou uma relevante melhoria de desempenho, através da distribuição da carga, criando e executando as threads em paralelo. No entanto, quase nunca se recomenda a criação de threads de forma direta no código.
Sendo assim, foi criado o tipo Task, que possibilita a execução de código em paralelo, sem precisar lidar com a complexidade do gerenciamento direto das threads:
public long IsPrimeWithTaskRunning() { long result = 0; var range = _endNumber - _startNumber; var numberOfTasks = Environment.ProcessorCount; var tasks = new Task[numberOfTasks]; var chunkSize = range / numberOfTasks; for (var i = 0; i < numberOfTasks; i++) { var chunkStart = _startNumber + chunkSize * i; var chunkEnd = i == numberOfTasks - 1 ? _endNumber : chunkStart + chunkSize; tasks[i] = Task.Run(() => { for (var number = chunkStart; number < chunkEnd; number++) { if (IsPrime(number)) { Interlocked.Increment(ref result); } } }); } Task.WaitAll(tasks); return result; }
Esta solução apresentou um tempo médio de execução de 87.35 milissegundos, aproximadamente 25% mais rápido que a segunda solução. O motivo da melhoria está no código Task.Run, que utiliza o thread pool por debaixo do capô, delegando o gerenciamento das threads, que reaproveita threads já criadas para a execução das tarefas.
Solução #4 – Descendo o nível de abstração
Na terceira solução foi utilizada a chamada Task.Run, aproveitando as vantagens de gerenciamento realizadas pelo thread pool. Mas, e se descer o nível de abstração, e utilizar diretamente a classe ThreadPool, qual é o resultado?
public long IsPrimeWithThreadpool() { long result = 0; long completedThreads = 0; var allDone = new ManualResetEvent(initialState: false); var range = _endNumber - _startNumber; var numberOfThreads = Environment.ProcessorCount; var chunkSize = range / numberOfThreads; for (var i = 0; i < numberOfThreads; i++) { var chunkStart = _startNumber + chunkSize * i; var chunkEnd = i == numberOfThreads - 1 ? _endNumber : chunkStart + chunkSize; var resetEvent = new ManualResetEvent(initialState: false); ThreadPool.QueueUserWorkItem(_ => { for (var number = chunkStart; number < chunkEnd; number++) { if (IsPrime(number)) { Interlocked.Increment(ref result); } } if (Interlocked.Increment(ref completedThreads) == numberOfThreads) { allDone.Set(); } }); } allDone.WaitOne(); return result; }
Esta implementação demonstra que é possível enfileirar uma tarefa diretamente no thread pool, através da chamada ThreadPool.QueueUserWorkItem. O tempo médio de execução foi de 85.90 milissegundos, apresentando pouco ganho de desempenho se comparado com a terceira solução.
Vale destacar que foi necessário incluir a classe ManualResetEvent e mais um controle de sincronização Interlocked.Increment(ref completedThreads), para garantir que a execução só será finalizada após todas as threads completarem suas tarefas.
Solução #5 – Simplificando o código
Em seu mais alto nível de abstração de paralelismo, o .NET oferece recursos que combinam simplicidade e bom desempenho, através da classe Parallel:
public long IsPrimeWithParrallelFor() { long result = 0; Parallel.For(_startNumber, _endNumber, number => { if (IsPrime(number)) { Interlocked.Increment(ref result); } }); return result; }
Esta implementação é quase tão simples quanto à primeira solução (for sequencial). O resultado do tempo médio de execução foi de 68.45 milissegundos, apresentando o melhor desempenho dentre as soluções apresentadas, mostrando-se aproximadamente 4 vezes mais rápida que a com for sequencial.
Resultado apresentado pelo benchmark:
|
Interessante observar, que para este cenário, a implementação mais simples de paralelismo foi a que apresentou o melhor desempenho. Comumente, as soluções tendem a ser mais complexas à medida que se busca melhor desempenho. |
//TODO
A distribuição do trabalho em threads, que executam paralelamente e de forma independente, pode auxiliar no alcance de uma melhoria significativa de desempenho, demandando apenas pequenas alterações no código. Entretanto, não combina bem com qualquer cenário, sendo necessário algumas reflexões:
- O ambiente onde a aplicação executa possui múltiplos processadores?
- O tipo de trabalho a ser realizado pode acontecer de forma distribuída e independente?
- A aplicação compartilha recursos com outros sistemas? Existe uma frequente concorrência de processadores entre as aplicações?
- Foram realizados testes e coleta de métricas, comprovando que a implementação com paralelismo apresenta melhora de desempenho?
Muito top esse capítulo. Você explicou de forma clara e objetiva quando devemos utilizar paralelismos e suas desvantagens.
parabéns. 🎉
Animado para próximos capítulos 👏